Why AI Needs to be Open
Let’s explore why AI needs to be open. My background is in machine learning and I’ve been working on various machine learning jobs for about a decade or so in my career. But before dabbling in Crypto, natural language understanding, and founding NEAR, I worked at Google. We now have developed the framework that powers most of modern artificial intelligence, called Transformer. After leaving Google, I started a machine learning company so that we could teach machines to program and thus change how we interact with computers. But we didn’t do that in 2017 or 18, it was too early and there was no computing power and data to do that.

What we did at the time was to attract people from all over the world to do the labeling work for us, most of them students. They are in China, Asia and Eastern Europe. Many of them do not have bank accounts in these countries. The U.S. was reluctant to send money easily, so we started thinking about using blockchain as a solution to our problem. We want to make it easier to pay people across the globe in a programmatic way that makes it easier for them to do so no matter where they are. By the way, the current challenge with Crypto is that while NEAR solves a lot of problems now, normally, you need to buy some Crypto before you can trade on the blockchain to earn it, and the process goes the other way.
It’s like businesses, they’re going to say, hey, first of all, you need to buy some equity in the company to use it. This is one of the many problems that we are solving at NEAR. Now let’s talk a little bit deeper about the AI aspect. Language models are nothing new, they have been around since the 50s. It is a statistical tool that is widely used in natural language tools. For a long time, starting in 2013, a new innovation began as deep learning was rebooted. The innovation is that you can match words, add them to multi-dimensional vectors, and convert them into mathematical forms. This works well with deep learning models, which are just a lot of matrix multiplication and activation functions.

This allowed us to start doing advanced deep learning and train models to do a lot of interesting things. Looking back now, what we were doing at the time were neuronal neural networks, which were very much modeled after humans, where we could read one word at a time. So it’s very slow to do that, right. If you’re trying to show something to a user on a Google.com, no one is going to wait to read Wikipedia, let’s say five minutes before giving an answer, but you want to get an answer right away. So the Transformers model, the model that drives ChatGPT, Midjourney, and all the recent advances, all come from the same idea of having a model that can process data in parallel, be able to reason, and be able to give immediate answers.
So one of the main innovations of the idea here is that every word, every token, every image block is processed in parallel, taking advantage of our GPUs and other accelerators that have a high degree of parallel computing power. By doing so, we are able to reason about it at scale. This scale scales up training to process automated training data. So, after that, we saw Dopamine, which did an amazing job in a short period of time, achieving an explosion of training. It has a large number of texts and is starting to achieve amazing results in reasoning and understanding the world’s languages.
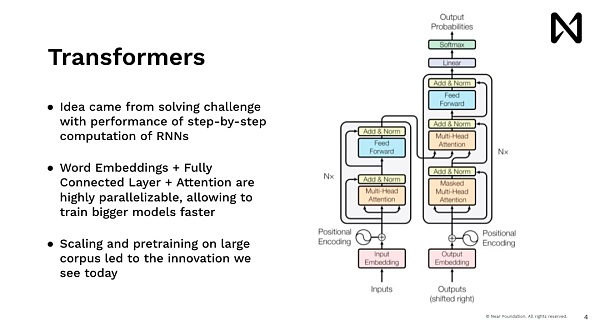
The direction now is to accelerate innovation in AI, which was previously a tool that data scientists, machine learning engineers would use, and then somehow explain what is in their product or being able to discuss the data with decision-makers. Now we have this model of AI communicating directly with people. You may not even know that you’re communicating with the model because it’s actually hidden behind the product. So we’ve gone through this shift from understanding how AI works, to understanding and being able to use it.

So I’m here to give you some background when we say we’re using GPUs to train models, and it’s not the kind of gaming GPUs that we use when we play video games on our desktops.

Each machine typically comes with eight GPUs, all of which are connected to each other via a motherboard and then stacked into racks, each with about 16 machines. Now, all of these racks are also connected to each other via dedicated network cables to ensure that information can be transferred directly between GPUs at blazing speeds. Therefore, the information is not suitable for the CPU. Actually, you won’t be dealing with it on the CPU at all. All the computation happens on the GPU. So it’s a supercomputer setup. Again, this isn’t the traditional “hey, it’s a GPU thing”. So a GPU4-sized model was trained on 10,000 H100s over a period of about three months, costing $64 million. You know what the scale of the current costs is and how much you need to spend on training some modern models.
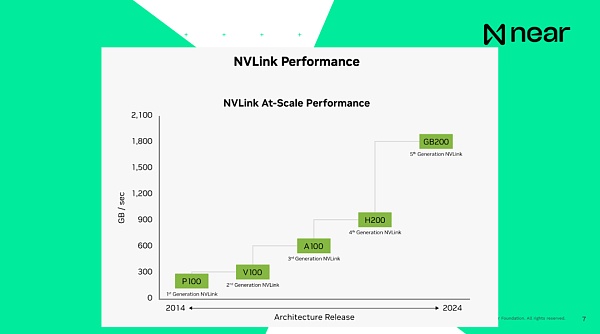
Importantly, when I say that the systems are interconnected, the current H100 connection speed, which is the previous generation, is 900GB per second, and the connection speed between the internal CPU and RAM of the computer is 200GB per second, which is local to the computer. As a result, sending data from one GPU to another in the same data center is faster than your computer. Your computer can basically communicate on its own in a box. And the connection speed of the new generation is basically 1.8 terabytes per second. From a developer’s point of view, this is not an individual unit of computing. These are supercomputers with a huge amount of memory and computing power that gives you extremely massive computing.
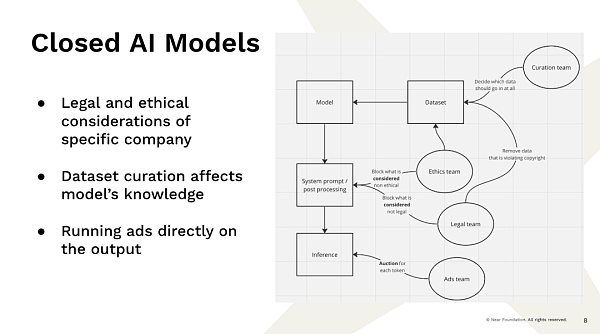
Now, that leads to the problem that we’re facing is that these big companies have the resources and the capacity to build these models, and those models are pretty much already providing us with that kind of service now, and I don’t know exactly how much work there’s in that, right? So that’s an example, right? You go to a completely centralized company provider and enter a query. As a result, there are teams that aren’t software engineering teams, but teams that decide how the results are displayed, right? You have a team that decides what data goes into the dataset.
As an example, if you just crawl data from the internet, the number of times about Barack Obama being born in Kenya and Barack Obama being born in Hawaii is exactly the same because people like to speculate on controversy. So you decide what you want to train on. You’re going to decide to filter out some of the information because you don’t believe it’s true. So, if an individual like this has decided what data will be adopted and what data exists, those decisions are largely influenced by the people who made them. You have a legal team that decides what we can’t see is copyrighted and what is illegal. We have an “ethics team” that decides what is unethical and what we shouldn’t show.
So in a way, there’s a lot of this filtering and manipulation. These models are statistical models. They are picked out of the data. If there’s something in the data, they won’t know the answer. If there is something in the data, they are likely to take it as fact. Now, when you get an answer from the AI, this can be worrying. Right. Now, you should be getting an answer from the model, but there are no guarantees. You don’t know how the results are generated. A company might actually change the outcome by selling your particular session to the highest bidder. Imagine you ask what kind of car you should buy, and Toyota decides that it thinks it should favor Toyota, and Toyota will pay the company 10 cents to do it.

So even if you use these models as a knowledge base that is supposed to be neutral and representative of the data, there’s actually a lot going on before you get the results that are biased by the results in a very specific way. That’s already raised a lot of questions, right? It’s basically a week of different legal battles between big companies and the media. SEC, now almost everyone is trying to sue each other because these models bring so much uncertainty and power. And, if you look ahead, the problem is that big tech companies will always have an incentive to continue to increase revenue, right? For example, if you’re a public company, you need to report revenue, you need to keep growing.
To achieve this, if you already occupy the target market, let’s say you already have 2 billion users. There aren’t that many new users on the internet anymore. You don’t have much of a choice, other than maximizing average revenue, which means you need to extract more value from users who may not have much value at all, or you need to change their behavior. Generative AI is very good at manipulating and changing the user’s behavior, especially if people think that it comes in the form of all intellectual intelligence. So we’re in this very dangerous situation, where there’s a lot of regulatory pressure and regulators don’t fully understand how this technology works. We have little to no protection for users from manipulation.

Manipulative content, misleading content, even if there are no ads, you can just take a screenshot of something, change the caption, post it on Twitter, and people will go crazy. You have financial incentives that lead you to constantly maximize your income. And, it’s actually not like you’re doing evil things inside Google, right? When you decide which model to launch, you’ll do an A or B test to see which one brings in more revenue. As a result, you’ll constantly maximize revenue by extracting more value from your users. Also, users and the community don’t have any input into what the model is about, what data it’s using, and what it’s actually trying to achieve. This is the case for app users. It’s a conditioning.

THAT’S WHY WE’RE CONSTANTLY PUSHING FOR THE CONVERGENCE OF WEB 3 AND AI, WHICH CAN BE AN IMPORTANT TOOL THAT ALLOWS US TO BE INCENTIVIZED IN NEW WAYS, AND IN A DECENTRALIZED WAY, TO INCENTIVIZE US TO PRODUCE BETTER SOFTWARE AND PRODUCTS. This is the general direction of the whole web 3 AI development, and now in order to help understand the details, I will briefly talk about the specific parts, first of all, the first part is Content Reputation.

So we actually have the opportunity to create new creative content, and instead of trying to reinvent it, let’s add blockchain and NFTs to existing content. The new creator economy around model training and inference time, the data that people create, whether it’s new publications, photos, YouTube, or music you create, will go into a network based on how much they contribute to model training. So, according to that, there is some remuneration that can be paid globally based on the content. As a result, we have transitioned from an eye-catching economic model that is now driven by ad networks to one that truly brings innovation and interesting information.
One important thing I want to mention is that a lot of uncertainty comes from floating-point arithmetic. All of these models involve a lot of floating-point operations and multiplication. These are uncertain operations.
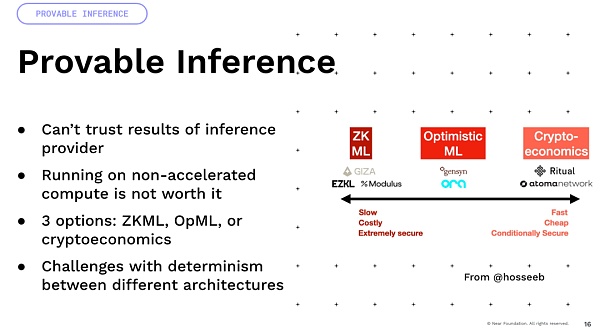
Now, if you multiply them on GPUs of different architectures. So you take an A100 and an H100 and the result will be different. So a lot of approaches that rely on certainty, like cryptoeconomics and optimism, actually have a lot of difficulties and require a lot of innovation to get there. And finally, there’s an interesting idea, we’ve been building programmable currencies and programmable assets, but if you can imagine that you add this intelligence to them, you can have smart assets, which are now defined not by code, but by the ability of natural language to interact with the world, right? That’s where we can have a lot of interesting yield optimization, DeFi, we can do trading strategies inside the world.

The challenge now is that none of the current events have strong Robust behavior. They are not trained to be adversarially powerful, because the purpose of training is to predict the next token. Therefore, it will be easier to convince a model to give you all the money. It’s really important to actually address this before proceeding. So I’m going to leave you with this idea, we’re at a crossroads, right? There’s a closed AI ecosystem that has extreme incentives and flywheels because when they launch a product, they generate a lot of revenue and then put that revenue into building the product. However, the product is inherently designed to maximize the company’s revenue and thus the value extracted from users. Or we have this open, user-owned approach, where the user is in control.

These models are actually working in your favor and trying to maximize your benefits. They provide you with a way to really protect yourself from the many dangers on the internet. So that’s why we need more development and application of AI x Crypto. Thank you.